Concatenative languages use juxtaposition of expressions for function composition.

The point-free programming paradigm is where function definitions do not identify the arguments on which they operate, all terms denote unary functions applied on a stack or a queue.
Fizzbuzz, in Uxntal.
#6501
@fizzbuzz ( n i -- )
#00
OVR #03 DIVk MUL SUB ?{ INC
LIT2 "F 18 DEO LIT2 "i 18 DEO LIT2 "z 18 DEOk DEO }
OVR #05 DIVk MUL SUB ?{ INC
LIT2 "B 18 DEO LIT2 "u 18 DEO LIT2 "z 18 DEOk DEO }
?{
DUP #0a DIVk #30 ADD #18 DEO
DIVk MUL SUB #30 ADD #18 DEO }
#0a18 DEO
INC GTHk ?fizzbuzz POP2 BRK
Fizzbuzz, in Rejoice.
times^100 f b @Loop ( times -- ) [num f b .FizzBuzz\n Loop]/[times f^3 b^5] [num f b .Fizz\n Loop]/[times f^3] [num f b .Buzz\n Loop]/[times b^5] [num f b .#num .\n Loop]/times
Truth be told, the amount of good research into concatenative languages is nearly non-existent.
Forth is a programming language that uses two stacks and a dictionary of words.
A Forth environment combines the compiler with an interactive shell, where the user defines and runs subroutines called words. Words can be tested, redefined, and debugged as the source is entered without recompiling or restarting the whole program.
Forth programmers enjoy the immediacy of an interpreter while at the same time the performance and efficiency of a compiler.

My principal forth environment is Felix Winkelmann's UF, a wonderful little graphical forth environment running on the Uxn virtual machine. I also sometimes use a custom version of the lbforth.c REPL, modified to work on Plan9(ARM) which can be downloaded here.
Basics
Forth reads from left to right, spaces are separators, when you wish to quit, type BYE. A stack is a way of managing data. With a stack, data is added to and taken from the "top", as with a stack of dishes. The acronym for this is LIFO: Last In First Out.
To inspect the stack, type .S
10 20 30 .S 30 20 10 OK DROP .S 20 10 OK BYE
Forth has no operator precedence, and does not need parentheses.
| Reverse Polish | Infix |
|---|---|
| 3 4 + 2 * | (3 + 4) * 2 |
| 2 3 4 * + | (3 * 4) + 2 |
| 2 3 * 4 + | (2 * 3) + 4 |
| 5 6 + 7 * | (5 + 6) * 7 |
Words
The dictionary comes with the Forth system. The programmer writes a program by adding to the dictionary words defined in terms of words in the dictionary. As a rule, Forth finds a word by starting with the most recently defined word and working backwards. If two or more words in the dictionary have the same name, Forth will find the most recently defined and be satisfied.
A colon definition starts with the Forth word :
: HELLO ." Hi! " ; HELLO Hi! OK
Because in Forth data is passed implicitly, it is considered insane to define a word without documenting what data it takes from the stack and what data it returns to the stack. The canonical way of doing this is to use the Forth word ( which tells the system to ignore what follows up to and including the next ). Expectations ("before") and results ("after") are separated by --. The resulting ( before -- after ) is a "stack-effect comment".
: SQUARED DUP * ; 5 SQUARED . 25
You program in Forth by teaching a machine new actions that you and the machine know by name. Each new action is a novel arrangement of known actions, perhaps mixing in some data. By being added to the dictionary the new action can be used to teach still newer actions.
: SQUARED ( n -- n**2 ) DUP * ; : CUBED ( n -- n**3 ) DUP SQUARED * ; : 4TH ( n -- n**4 ) SQUARED SQUARED ;
Logic
There’s actually no boolean type in Forth. The number 0 is treated as false, and any other number is true, although the canonical true value is -1 (all boolean operators return 0 or -1). Conditionals in Forth can only be used inside definitions.
The simplest conditional statement in Forth is if then, which is equivalent to a standard if statement in most languages. Here’s an example of a definition using if then. In this example, we’re also
using the mod word, which returns the modulo of the top two numbers on the stack. In this case, the top number is 5, and the other is whatever was placed on the stack before calling buzz?. Therefore, 5 mod 0 = is a boolean expression that checks to see if the top of the stack is divisible by 5.
: BUZZ? 5 MOD 0 = IF ." BUZZ" THEN ;
Loops
: STAR [CHAR] * EMIT ; : STARS 0 DO STAR LOOP CR ; 10 STARS **********
Stack Primitives
Stack machines are arguably the simplest kind architecture. Their LIFO structure is quite suitable for block-oriented languages. The code size for a stack machine can be very compact because most instructions have no operand field.
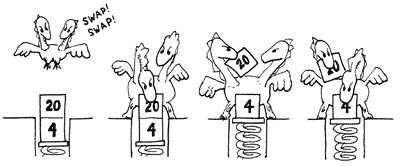
POPRemove an item at index, closing the hole left in the stack.ROLLRemove an item at index, push it on top of the stack.PICKCopy an item at index, push it on top of the stack.
Given the Last In First Out stack a b c, here are the resulting stacks after each primitive:
| Primary | Secondary | Definition | ||
| POP | 0 | DROP | a b | Discard top item. |
|---|---|---|---|---|
| 1 | NIP | a c | Discard second item. | |
| ROLL | 0 | SWAP | a c b | Bring second item to top. |
| 1 | ROT | b c a | Bring third item to top. | |
| PICK | 0 | DUP | a b c c | Copy top item. |
| 1 | OVER | a b c b | Copy second item to top. | |
Bestiary
| Single Items | |
|---|---|
| drop/pop/zap | ( a -- ) |
| nop | ( a -- a ) |
| dup | ( a -- a a ) |
| nip | ( a b -- b ) |
| swap | ( a b -- b a ) |
| over/peek | ( a b -- a b a ) |
| tuck | ( a b -- b a b ) |
| rot/dig | ( a b c -- b c a ) |
| -rot/bury | ( a b c -- c a b ) |
| poke/snatch | ( a b c -- b c ) |
| flip/spin | ( a b c -- c b a ) |
| roll | ( a b c d -- b c d a ) |
| -roll | ( a b c d -- d a b c ) |
| Quoted Items | |
| unit | ( a -- [a] ) |
| identity | ( [a] -- a ) |
| rep | ( [a] -- a a ) |
| run | ( [a] -- a [a] ) |
| cons | ( a [b] -- [a b] ) |
| sons | ( a [b] -- [a b] a ) |
| dip | ( a [b] -- b a ) |
| cat/compose | ( [a] [b] -- [a b] ) |
| sap | ( [a] [b] -- b a ) |
| swat/prepose | ( [a] [b] -- [b a] ) |
| take | ( [a] [b] -- [b [a]] ) |
| tack | ( [a] [b] -- [a [b]] ) |
| sip | ( b [a] -- b a b ) |
| cake | ( a [b] -- [a b] [b a] ) |
A generalized stack operator %abc, is sometimes used to represent the transformation, for example, %ba is the same as swap, %aa is the same as dup and %bab is the same as over.

Minimal Forth Architectures
In The Road Towards A Minimal Forth Architecture, Mikael Patel builds toward a forth from only a handful of arithmetic and stack primitives. Here is an implementation of some of these primitives in Uxntal macros.
%t! ( v -- ) { .t STZ }
%t@ ( -- v ) { .t LDZ }
%r> ( | v -- v ) { STHr }
%>r ( v -- | v ) { STH }
%1+ ( x -- x+1 ) { INC }
%0= ( x -- flag ) { #00 EQU }
%nand ( x y -- z ) { AND #ff EOR }
%exit ( -- ) { BRK }
%minint { #80 }
%drop ( v -- ) { t! }
%dup ( v -- vv ) { t! t@ t@ }
%swap ( ab -- ba ) { t! >r t@ r> }
%nip ( ab -- b ) { >r t! r> }
%over ( ab -- aba ) { >r t! t@ r> t@ }
%tuck ( ab -- bab ) { t! >r t@ r> t@ }
%rot ( abc -- bca ) { >r >r t! r> r> t@ }
%2swap ( abcd -- cdab ) { >r t! >r >r t@ r> r> r> t! >r >r t@ r> r> }
%2dup ( ab -- abab ) { t! t@ t@ >r >r t! t@ r> t@ r> }
%2over ( abcd -- abcdab ) { >r >r 2dup r> r> 2swap }
%2drop ( ab -- ) { t! t! }
%3rev ( abc -- cba ) { t! >r t@ >r t! r> r> t@ }
%4rev ( abcd -- dcba ) { t! >r t@ >r t! r> r> t@ >r >r >r t! r> r> r> t@ }
%third ( abcd -- abca ) { >r >r t! t@ r> r> t@ }
%fourth ( abcd -- abcda ) { >r >r >r t! t@ r> r> r> t@ }
%3dup ( abc -- abcabc ) { third third third }
%not ( a -- b ) { dup nand }
%and ( a b -- c ) { nand not }
%or ( a b -- c ) { not swap not nand }
%xor ( a b -- c ) { over over not nand >r swap not nand r> nand }
%r@ ( | x -- x | x ) { r> r> dup >r swap >r }
%1- ( x -- y ) { not 1+ not }
%2+ ( x -- y ) { 1+ 1+ }
%2- ( x -- y ) { not 2+ not }
%negate ( x -- y ) { not 1+ }
%boolean ( x -- flag ) { 0= 0= }
%0< ( x -- flag ) { minint and boolean }
%0> ( x -- flag ) { dup 0< swap 0= or not }
%sub ( x y -- z ) { negate ADD } ( bypass )
%equal ( x y -- flag ) { sub 0= }
%lesser ( x y -- flag ) { sub 0< }
%greater ( x y -- flag ) { sub 0> }
|000 @t $1
|100
#06 2-
#010e DEO
BRK
Chuck Moore also uses a pared down Forth for his custom minimal-instruction set processors. They are an inspiration for designing other minimal languages. For example, his latest designs have five-bit instructions, for 32 possible opcodes:
| Stack | DROP, DUP, OVER, PUSH, POP |
|---|---|
| Math | +, AND, XOR, NOT, 2*, 2/, multiply-step |
| Call | JUMP, CALL, RETURN, IF, -IF |
| Loop | NEXT, UNEXT |
| Register | A, A!, B! |
| Memory | @, !, @+, !+, @B, !B, @P, !P |
| NO-OP | . |
- Forth Tutorial
- Original lbforth
- Forth Methodology
- Forth Primitives
- Language for Thoughtful Programming
- Forth History
- Design Decisions in the Forth Kernel
- 3 Instructions Forth
- Linear Logic and Permutation Stacks
- The Language That Writes Itself, by Ratfactor
- Thoughts, by Felix Winkelmann
Live frogs are just very different
than dead frogs.
Postscript is a programming language that was designed to specify the layout of the printed page.
The Postscript language uses a postfix syntax similar to Forth.
Guide written by Paul Bourke, last updated December 1998.

Introduction
Postscript printers and postscript display software use an interpreter to convert the page description into the displayed graphics.
The following information is designed as a first tutorial to the postscript language. It will concentrate on how to use postscript to generate graphics rather than explore it as a programming language. By the end you should feel confident about writing simple postscript programs for drawing graphics and text. Further information and a complete specification of the language can be obtained from The Postscript Language Reference Manual from Adobe Systems Inc, published by Addison-Wesley, Reading, Massachuchusetts, 1985.
Why learn postscript, after all, many programs can generate it for you and postscript print drivers can print to a file? Some reasons might be:
- Having direct postscript output can often result in much more efficient postscript, postscript that prints faster than the more generic output from printer drivers.
- There are many cases where generating postscript directly can result in much better quality. For example when drawing many types of fractals where high resolution is necessary, being able to draw at the native high resolution of a postscript printer is desirable.
- It isn't uncommon for commercial packages to make errors with their postscript output. Being able to look at the postscript and make some sense of what is going on can sometimes give insight on how to fix the problem.
The Basics
Postscript files are (generally) plain text files and as such they can
easily be generated by hand or as the output of user written programs.
As with most programming languages, postscript files (programs) are
intended to be, at least partially, human-readable. As such, they are
generally free format, that is, the text can be split across lines and
indented to highlight the logical structure.
Comments can be inserted anywhere within a postscript file with the percent (%)
symbol, the comment applies from the % until the end of the line.
While not part of the postscript specification the first line of a
postscript file often starts as %!. This is so that spoolers and other
printing software detect that the file is to interpreted as postscript
instead of a plain text file. The inline example below will not include this
but the postscript files linked from this page will include it since they
are design for direct printing.
The first postscript command to learn is showpage, it forces the
printer to print a page with whatever is currently drawn on it. The examples
given below print on single pages and therefore there is a showpage at the end
of the file in each example, see the comments later regarding EPS.
A Path
A path is a collection of, possibly disconnected, lines and areas describing the image. A path is itself not drawn, after it is specified it can be stroked (lines) or filled (areas) making the appropriate marks on the page. There is a special type of path called the clipping path, this is a path within which future drawing is constrained. By default the clipping path is a rectangle that matches the border of the paper, it will not be changed during this tutorial.
The Stack
Postscript uses a stack, otherwise known as a LIFO (Last In First Out) stack to store programs and data. A postscript interpreter places the postscript program on the stack and executes it, instructions that require data will read that data from the stack. For example, there is an operator in postscript for multiplying two numbers, mul. it requires two arguments, namely the two numbers that are to be multiplied together. In postscript this might be specified as
10 20 mul
The interpreter would place 10 and then 20 onto the stack. The operator mul would remove 20 and then 10 from the stack, multiply them together and leave the result, 200, on the stack.
Coordinate system
Postscript uses a coordinate system that is device independent, that is, it doesn't rely on the resolution, paper size, etc of the final output device. The initial coordinate system has the x axis to the right and y axis upwards, the origin is located at the bottom left hand corner of the page. The units are of "points" which are 1/72 of an inch long. In other words, if we draw a line from postscript coordinate (72,72) to (144,72) we will have a line starting one inch in from the left and right of the page, the line will be horizontal and be one inch long.
The coordinate system can be changed, that is, scaled, rotated, and translated. This is often done to form a more convenient system for the particular drawing being created.
Basic Drawing Commands
Time to draw something. The following consists of a number of operators and data, some operators like newpath don't need arguments, others like lineto take two arguments from the stack. All the examples in this text are shown as postscript on the left with the resulting image on the right. The text on the left also acts as a link to a printable form of the postscript file.
newpath 100 200 moveto 200 250 lineto 100 300 lineto 2 setlinewidth stroke
There are also a relative moveto and lineto commands, namely, rmoveto and rlineto.
In this next example a filled object will be drawn in a particular shade, both for the outline and the interior. Shades range from 0 (black) to 1 (white). Note the closepath that joins the first vertex of the path with the last.
newpath 100 200 moveto 200 250 lineto 100 300 lineto closepath gsave 0.5 setgray fill grestore 4 setlinewidth 0.75 setgray stroke
The drawing commands such as stroke and fill destroy the current path, the way around this is to use gsave that saves the current path so that it can be reinstated with grestore.
Text
Text is perhaps the most sophisticated and powerful aspect of postscript, as such only a fraction of its capabilities will be discussed here. One of the nice things is that the way characters are placed on the page is no different to any other graphic. The interpreter creates a path for the character and it is then either stroked or filled as per usual.
/Times-Roman findfont 12 scalefont setfont newpath 100 200 moveto (Example 3) show
As might be expected the position (100,200) above specifies the position of the bottom left corner of the text string. The first three lines in the above example are housekeeping that needs to be done the first time a font is used. By default the font size is 1 point, scalefont then sets the font size in units of points (1/72 inch). The brackets around the words "Example 3" indicate that it is a string.
A slightly modified version of the above uses charpath to treat the characters in the string as a path which can be stroked or filled.
/Times-Roman findfont 32 scalefont setfont 100 200 translate 45 rotate 2 1 scale newpath 0 0 moveto (Example 4) true charpath 0.5 setlinewidth 0.4 setgray stroke
You should make sure you understand the order of the operators above and the resulting orientation and scale of the text, procedurally it draws the text, scale the y axis by a factor of 2, rotate counter clockwise about the origin, finally translate the coordinate system to (100,200).
Colour
For those with colour LaserWriters the main instruction of interest that replaces the setgray is previous examples is setrgbcolor. It requires 3 arguments, the red-green-blue components of the colour each varying from 0 to 1.
newpath 100 100 moveto 0 100 rlineto 100 0 rlineto 0 -100 rlineto -100 0 rlineto closepath gsave 0.5 1 0.5 setrgbcolor fill grestore 1 0 0 setrgbcolor 4 setlinewidth stroke
Programming
As mentioned in the introduction postscript is a programming language.
The extend of this language will not be covered here except to show
some examples of procedures that can be useful to simplify postscript
generation and make postscript files smaller.
Lets assume one needed to draw lots of squares with no border but
filled with a particular colour. One could create the path repeatedly
for each one, alternatively one could define something like the following.
/csquare {
newpath
0 0 moveto
0 1 rlineto
1 0 rlineto
0 -1 rlineto
closepath
setrgbcolor
fill
} def
20 20 scale
5 5 translate
1 0 0 csquare
1 0 translate
0 1 0 csquare
1 0 translate
0 0 1 csquare
This procedure draws three coloured squares next to each other, each 20/72 inches square, note the scale of 20 on the coordinate system. The procedure draws a unit square and it expects the RGB colour to be on the stack. This could be used as a method (albeit inefficient) of drawing a bitmap image.
Even if one is simply drawing lots of lines on the page, in order to reduce the file size it is common to define a procedure as shown below. It just defines a single character "l" to draw a line segment, one can then use commands like 100 200 200 200 l" to draw a line segment from (100,200) to (200,200).
koch.ps
%!PS-Adobe-3.0 EPSF-3.0
/koch {
dup depth le { % s < depth
1 add exch % s => s+1
3 div exch % t => t/3
% t/3 s+1 60 t/3 s+1 240 t/3 s+1 60 t/3 s+1
60 3 copy 180 add 3 copy 180 sub 3 copy pop
koch rotate koch rotate koch rotate koch
}
{ pop 0 rlineto } % draw
ifelse
} def
4.0 4.0 scale
/depth 5 def
0.1 setlinewidth
newpath
20 100 moveto
100 1 koch stroke
showpage
Rejoice!
Rejoice is a concatenative programming language in which logic and arithmetic emerge entirely from the application of fractions. Think Fractran, without the rule-searching, or Forth without a stack.
Basics
- The program state is a bag of unordered things where elements are combined by union and
^ndenotes multiplicity. For example, the bag[cube cone^3]contains one cube, and three cones. The empty bag is represented as[]. - Symbols are things in the bag written as either numeric decimal integers or names representing prime values. For example, the bag
[8 ball^2]and[2^3 ball ball]are equal. - Transformations are represented as fractions in which the denominator indicates things to remove from the bag, and the numerator, the things to add. For example,
owl/cat^2means to replace twocatswith oneowl.
A program is a sequence of instructions, separated by spaces, written in the postfix notation. Each instruction is a fraction that corresponds to an exchange of resources on a list of unsorted symbols. The empty bag [] is identity; x/[] always applies, and []/x only applies when x is found in the bag.
3 4 + 2 - . ( In Forth )
n^3 n^4 []/n^2 .#n( In Rejoice )
Evaluation consists of applying each fraction in a sequence, when the contents of the denominator are found in the bag: these are removed from the bag and the contents of the numerator are added to the bag; otherwise the fraction is skipped having had no effect.
[cat bat rat^2] ( I have 1 cat, 1 bat and 2 rats )
[cat bat^3]/rat ( If I have 1 rat, I replace it with 1 cat & 3 bats )
[]/[rat cat^2] ( If I have 1 rat and 2 cats, I discard them )
yak/bat^cat ( If I have at least as many bats as cats..
.. I replace the amount of cats in bats with 1 yak )
[bat^4 yak] ( I am left with 4 bats and 1 yak )
Execution is a single sequential pass over the program data, each instruction is attempted exactly once in order and the program halts when the program counter reaches the end of the program.
Logic
Logic is implemented by sequencing fractions for each possible state of the gate. The fractions consume a dedicated symbol, which we'll call a sentinel, to ensure only one clause fires. For example, here is the implementation of a NOT logic gate:
false not true/[false not] false/[true not]
[false not] true/[false not] false/[true not] [true] false/[true not] [true]
The different cases are sequenced one after the other, here is a OR gate. Note the need for a sentinel symbol, or, that persists through each case, without which, the false case could not be reached.
x y or true/[x y or] true/[x or] true/[y or] false/or
Lastly, here is an AND gate which also needs a sentinel symbol to capture the state when both inputs aren't present in the bag.
x y and true/[x y and] false/[x and] false/[y and] false/and
Variable Exponents
Numbers are stored as counts, for example, x^5 indicates five instances of x. Variable exponents are symbols used as the exponent value in a fraction. For a fraction containing x^y, the value of y is read as the number of instances of the symbol y in the bag resolved when the fraction is evaluated. When a symbol used as an exponent is absent from the bag, its value is zero. For example, to find the sum of two values, the program creates as many instances of x as there are of y, and then drain the left-over instances of y:
x^2 y^5 ( Copy y instances onto x, then drain y: ) x^y []/y^y
[x^2 y^5] x^y []/y^y [x^7 y^5] []/y^y [x^7]
To find the difference between two values, the program removes as many instances of x as there are of y:
x^5 y^2 ( Remove as many x as there are y, then drain y: ) []/x^y []/y^y
[x^5 y^2] []/x^y []/y^y [x^3 y^2] []/y^y [x^3]
All variable exponents within a single bracket are resolved simultaneously against an atomic read of the bag. No symbol inside a bracket can observe the effects of any other symbol in the same bracket. For example, the following finds whether x is equal to y:
x^6 y^6 ( Fires only when x and y are equal counts, consuming both: ) eq/[x^y y^x]
[x^6 y^6] eq/[x^y y^x] [eq]
- False?:
( a -- true|a ) true/nil^a - Equal?:
( a b -- true|[a b] ) true/[a^b b^a] - Greater?:
( a b -- [true a^diff]|[a b] ) true/[a^b b^b]
Labels
A @label is a special syntax that represents position in the program. After each instruction, if a symbol matching the name of an existing label is present in the bag, the symbol is consumed, and execution jumps immediately to that label position. The capitalization of labels is merely a convention. For example, here is a program to find the product:
x^2 y^3 @Mul ( x y -- res ) [Mul res^x]/y
[x^2 y^3] [Mul res^x]/y [x^2 y^2 res^2] [Mul res^x]/y [x^2 y res^4] [Mul res^x]/y [x^2 res^6] [Mul res^x]/y [x^2 res^6]
When two labels enter the bag at the same time, one is picked at random. For example, a program that returns the result of a coin toss:
( flip a coin ) [Head Tail] @Head head End @Tail tail @End
Anonymous Functions
A common operation is to loop over a fraction until exhaustion. Anonymous functions are syntactic sugar so that fractions that are repeatedly applied until exhaustion don't need to be named. For example, here is a program to find the quotient:
x^24 y^6 'res/x^y
[x^24 y^6] 'res/x^y [x^18 y^6 res] 'res/x^y [x^12 y^6 res^2] 'res/x^y [x^6 y^6 res^3] 'res/x^y [y^6 res^4] 'res/x^y [y^6 res^4]
The Fibonacci numbers can be found with a single anonymous function, by swapping x and y while a counter n is present:
n^6 y ( n y -- n.fib y ) '[y^x x^y]/[x^x n]
[n^6 y] '[y^x x^y]/[x^x n] [n^5 y x] '[y^x x^y]/[x^x n] [n^4 y^2 x] '[y^x x^y]/[x^x n] [n^3 y^3 x^2] '[y^x x^y]/[x^x n] [n^2 y^5 x^3] '[y^x x^y]/[x^x n] [n y^8 x^5] '[y^x x^y]/[x^x n] [y^13 x^8] '[y^x x^y]/[x^x n] [y^13 x^8]
- Multiplication:
( x y -- x r=x*y ) 'r^x/y - Division:
( x y -- y r=x/y ) 'r/x^y - Square:
( x -- x res=x*x ) y^x '[res^x]/y - Modulo:
( x y -- x=x%y y ) '[]/x^y
I/O
Symbols that start with . will be emitted as text and immediately removed from the bag. Symbols that start with .# will emit the number of instances of that symbol in the bag. For example: A token like .hello^3 will emit hellohellohello.
pigs^3 ( print the word "pigs:" ) .pigs: ( print the number of pigs in decimal ) .#pigs
pigs:3
The supported escape sequences are: \t(tab), \s(space) and \n(linebreak). Input is done by adding special symbols in the bag before evaluation.
FizzBuzz
And lastly, this would not be complete without an example of FizzBuzz:
times^100 f b @Loop ( times -- ) [num f b .FizzBuzz\n Loop]/[times f^3 b^5] [num f b .Fizz\n Loop]/[times f^3] [num f b .Buzz\n Loop]/[times b^5] [num f b .#num .\n Loop]/times
1, 2, Fizz, 4, Buzz, Fizz, 7, 8, Fizz, Buzz, 11, Fizz, 13, 14, FizzBuzz ..
- Source, Uxntal.
- Repository, Uxntal.
- Read a translation in Peano's Latin Sin Flexion.
- Rewriting Mailinglist
- Multiset Languages: Fractran, Bägel.
[] es nihil, identitate. []/n es predecessore. n es successore.

incoming: m pc binary rejoice gaud fractran thuesday uxntal uxn devlog 2026 2024